What sucks in security? Research findings from 50+ security leaders
- Market research
22 minute read
This blog post is cross-posted on tl;dr sec and on Maya’s blog. This is a version of a talk that Maya gave at October’s SnooSec meetup – get the slides.
Throughout the fall of 2024, I interviewed 57 security leaders to understand their biggest pain points in our industry, which is to say, I asked them “What sucks in security?”. These weren’t just theoretical discussions – I wanted to know what is currently challenging for their teams and where they are choosing to invest their limited resources, as I investigate how I can best contribute to security – but they were sometimes bordering on CISO therapy sessions.
In each discussion, we covered their role, team structure, infrastructure choices, and priorities. But most importantly, I asked them where they are encountering problems in their security programs. Every conversation was different: I didn’t follow a perfect script and ask the same questions every time. So, the data I collected is often incomplete – it’s a great indication of broad trends in the industry, but not a perfect data set.
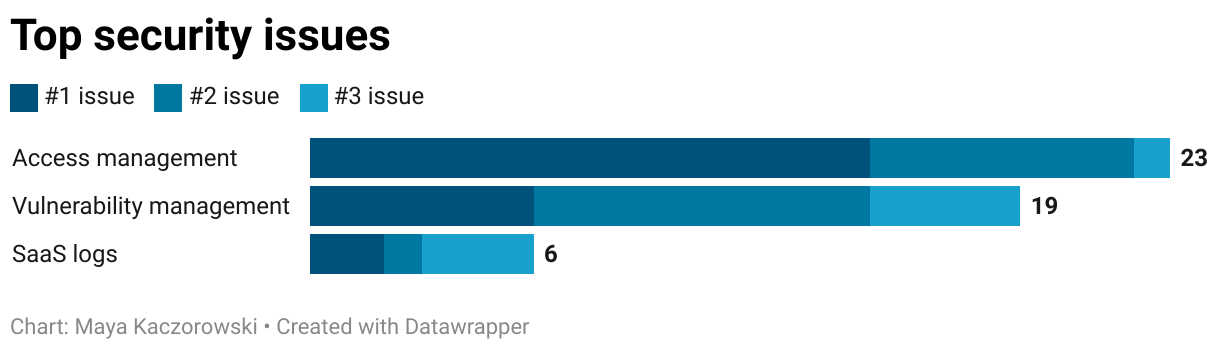
tl;dr: The top technology pain points are:
- Ticket-based and inconsistent access management,
- Disparate vulnerability prioritization and remediation workflows,
- And obtaining and using SaaS logs.
A proliferation of vendors, underclear ownership of services and assets, and the difficulty of successfully communicating and explaining security risks exacerbate other security problems.
Demographics
Through warm intros, I connected with primarily CISOs at tech-forward companies with 500 to 5,000 employees in the United States:
- I spoke to 29 CISOs, but also 25 other security leaders and practitioners responsible for some aspect of security in their organization, e.g., head of Cloud Security or head of SecOps. The remaining 3 interviewees were those who were the closest equivalent to a security leader in their organization, including a CTO, VP Eng, and CEO.
- Their organizations ranged from 30-person startups to 240,000 employee multinationals, with a median of 1,525 employees.
- Their security teams ranged from 1 to 300 people, with a median of 14. (The data is imperfect, as I didn’t always ask this question.) This means that the security team was from 0.7% to 7.5% of total employees in the organization.
There was definitely a bimodal distribution of companies I talked to, possibly reflecting the current market reality we’re in – at the first peak, a set of security-forward startups with a handful of security folks, and at at the second peak, a set of larger companies with a few thousand employees and a security organization with multiple teams.
The security team’s responsibilities sometimes but not always included IT. They usually included privacy engineering, where the organization had this function. And I observed a trend to move towards having the Data or BI team report to the CISO – an evolution of the role into more of a cross-functional platform team (separate from DevOps or infrastructure), rather than just security.
In addition to the data being incomplete, it is inherently biased – these are folks I was personally connected to, who are generally more security-minded than average, and who are generally at smaller, more experimental companies. This by no means is what the entire industry is experiencing, but can be thought of as a bellwether for where we might be headed.
Top security issues
I went through all of my conversation notes, and picked out the top complaints from each leader I spoke to, and then took the logical next step of making a word cloud. This is the first (and probably only) time I’ve made a word cloud for its intended purpose! Bask in its glory. (I feel bad for the CISO whose top issue was “team morale” – I hope your team is feeling better now.)

Looking at the themes from the top unprompted complaints from each CISO, three issues emerged consistently across conversations: access management, vulnerability management, and SaaS logs. Let’s see that chart again.
Access management
I can’t provision appropriately scoped access, so my team is overloaded with access request tickets.
Access management remains a critical challenge, with teams overwhelmed by access request tickets. Entitlement changes are highly manual, requiring approvals for even routine changes. The team reviewing these access requests, typically IT, lacks sufficient context to make informed decisions – the confused deputy problem.
One security leader described having 700+ access tickets a month, which are only successfully processed thanks to external IT support. Another CISO lamented that the trend to improving access ticket “approval is a pressure relief valve,” that has made the process of reviewing access requests faster, but hasn’t actually improved the underlying difficulties they have with access management.
Entitlements in most organizations have grown organically, which means that “identity is a whole mess.” Permissions are often granted ad hoc – one-off permission requests, teammates’ permissions cloned, and brash overprovisioning in order to quickly unblock the business – so they need constant tweaking. This issue continues to persist because, for the most part, we don’t know what someone should have access to.
This is made more complicated by the separation between corporate (corp) and production (prod) access controls, and the tension between the IT and security teams. Since IT typically manages corp access, and security typically manages prod access – but the security team doesn’t want the IT team to be able to grant access to prod – most organizations have multiple authorization systems that they have to manage. “You’re never going to be able to centralize all of your identity in one system.”
Vulnerability management
I have too many vulnerabilities to patch, so I need to prioritize these and ensure they are handled appropriately.
Security teams are overwhelmed with vulnerabilities. Teams are moving to minimal container base images (such as from Chainguard) and VM golden images, as well as forcing ongoing redeployments of containers or rebuilds of VMs in order to reduce a significant volume of vulnerabilities. In addition to this, in order to “eradicate types of vulnerability”, security leaders are partnering with their Eng leads to reduce the number of languages they use – reducing the ecosystems they need to support for scanning, as well as moving to memory-safe languages like Rust.
Despite undertaking these broad reductions in the volume of vulnerabilities, teams are still overwhelmed – some of these efforts might take years to realize. They’re looking to prioritize their vulnerabilities based on reachability, business context, and exploitability. For many security leaders, “reachability is a problem” – they want to know, “is the code used anywhere at all?” Tools like Zafran and Vulcan aim to help with exposure management, but no tool has wide deployment yet. It’s really hard to get business context without having sufficient reach, so point solutions fail where Wiz excels: being able to see where a vulnerability is in their environment, and more important, in what critical applications.
The challenge of dealing with the growing volume of vulnerabilities is made worse by disparate scanners and disjointed workflows. Many scanners are point solutions, so organizations need to deploy multiple tools to cover their entire environment, across more than just AppSec (say, an old version of Adobe Acrobat on a server). The lack of integrated tooling creates overhead, with teams juggling notifications across email, GitHub, and Slack, depending on the tool.
“The entire lifecycle of managing vulnerabilities feels off to me,” noted one participant: they don’t have a reasonable process to ingest, dedupe, prioritize and assign vulns at scale, across their environment, cross-functionally. Finding bugs is a technical problem, fixing them is a human problem. Back in the day, this workflow might have been JIRA and measured MTTR, but most participants I talked to didn’t have a ticketing system and were tracking remediation in good ol’ spreadsheets. (Who doesn’t love a spreadsheet?) The push to move to a more organized solution comes from the need to meet SLAs for handling vulns under FedRAMP control RA-5d: to remediate high vulnerabilities within 30 days. “Because we have FedRAMP, vulnerability management is a big thing.”
The industry is ripe for change. As one security leader observed, “We are at the point for vulnerability management that we were in 2010 with EDR.”
SaaS logs
When there’s an incident, I can’t easily pull the logs I need to find out what happened in my SaaS environments.
Investigating incidents in SaaS environments is hampered by a fundamental lack of visibility. Organizations have an exploding amount of SaaS apps. At the long tail, many SaaS providers don’t offer audit logs at all; and at the fat part of the tail, put them behind paywalls. Even when logs are available, they might be incomplete, like missing login events.
“A lot of SaaS solutions are not set up in a way where their logs are useful for monitoring” and vendors “don’t have logs like I want”. Furthermore, the lack of standardization across tools creates ingestion challenges. “Having a common SaaS format would be tremendous,” explained one participant. Every new SaaS tool the business buys requires custom work to fetch logs, normalize them, and write alerts.
The inability to stream logs, or even access them programmatically, rather than through web portals, makes real-time monitoring and analysis difficult. The delay to get logs is painful. I heard of someone needing to log in to Stripe to manually look at logs in their web portal, another person waiting 4 hours to fetch the relevant logs from Slack, another waiting 2 days after emailing Notion support to get logs related to a potential employee issue, and yet another emailing GitHub for logs – who was thankfully able to provide some support even though their pricing plan didn’t include those logs.
I suspect more leaders would have brought this issue up, but hadn’t yet felt the pain – this pain point is only really felt by security leaders who have had to deal with incidents involving their SaaS tools.
Cultural complications
Beyond the technical problems, there were several organizational challenges that were force multipliers: they compounded all other issues and made security even harder to deal with. The top complications were vendor sprawl, ownership, and explainability.
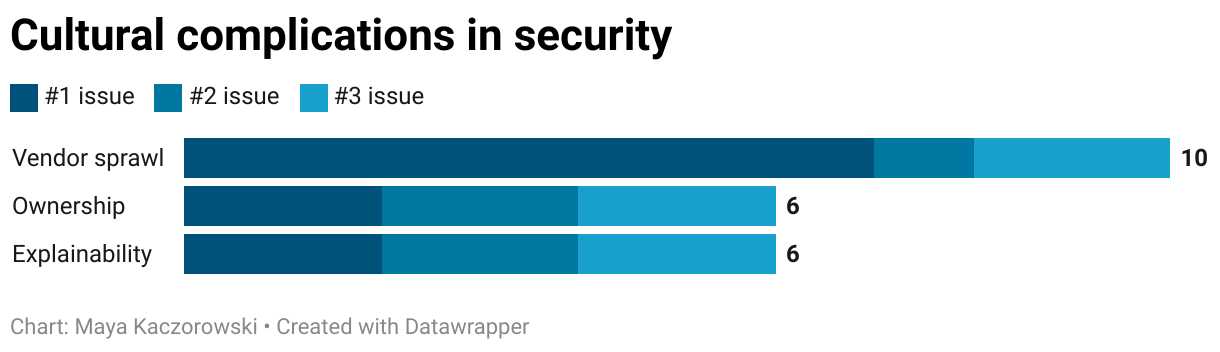
Vendor sprawl
I have too many vendors, and they don’t always work well together.
The security vendor market has become overwhelming, with too many similar tools and confusing marketing. When I asked what sucks in security, one CISO bluntly and immediately answered, “I fucking hate vendors.” (As someone who now emails you to ask for your time… I’m sorry.)
“There’s just so many vendors” in the security space. CISOs are “inundated” as vendors “just keep trying to sell me stuff.” It’s difficult to tell vendors apart from their marketing, and getting a working solution requires stringing together multiple point solutions, each being sold for a few dollars a seat – which quickly adds up.
As you adopt more tools, it’s not just costs that accumulate, but risks as well. Every new vendor is a new security risk that security teams are insufficiently equipped to assess – “vendor security is just a complete joke.” One leader saw startup tools as particularly risky: since “I have to take on their security debt… in order for me to even consider a vendor… [I need] their CEO’s phone.”
The proliferation of vendors in an organization also means it’s hard to get an overview of security.
As one CISO shared, “my biggest problem, bar none, is I have no single pane of glass.” Reporting is ad hoc, and there is no single place to go to understand overall security posture. “Everyone is doing one slice of the pie [and] everyone has a dashboard,” but they just want one.
And the proliferation of vendors in the industry means that everyone’s stack is just a little bit different, requiring integration work to get tools working in each environment. The need to invest in custom integrations makes teams increasingly hesitant to adopt new solutions, as noted by another participant: “I can’t waste time on integrating a new vendor.” This also explains why the security industry seems to be the source of connection tools like Tines, Merge and Leen, which act as the missing glue between tools.
Ownership
I can’t keep track of who owns our ever-expanding set of services, assets, and apps.
Tracking ownership of services, assets, and applications has become increasingly complex. “It’s quite social and messy… more gardening than construction,” as one participant described it. Missing service catalogs, incomplete asset inventories, and unclear SaaS application ownership create operational friction.
Most organizations (of the size I talked to) don’t have a service catalogue – but if they do, it’s probably Backstage. They don’t know which team owns a service, which makes it hard to know who to ask or assign the job of applying a patch, fixing a vulnerability, or knowing who to pull in during an incident. “One of our biggest challenges is attribution: who owns that thing?… This isn’t just a security problem.” It also makes maintenance hard – if someone leaves, no one wants to touch a system for fear of breaking it. “Some systems didn’t have an owner… nobody wanted to mess with them since they’d been around for so long.”
“A lot of people think asset management is solved,” but it’s not comprehensive enough to cover the new kinds of resources we deal with today. Most organizations have an asset catalogue, but they consider it incomplete: it covers end user devices, and maybe servers, but not cloud resources like AWS accounts, or GitHub repos. That’s where Cloud Custodian and CODEOWNERS are helping organizations keep track.
Furthermore, since all you need to purchase a SaaS tool is a credit card, there are SaaS applications in each organization that are not centrally managed. It’s not always clear who manages these applications, or if they’re effectively abandoned. “We have quite a few tools that don’t have owners, that are scary.” There’s a general agreement here that CASB as a concept has failed, and we’re seeing the next gen of SaaS security tools like Nudge Security and Reco help address this.
Explainability
I need to be able to communicate security risks and requirements effectively.
Security leaders face ongoing challenges in communicating risks and requirements to their organizations. To be clear: this is… err… (by definition) the CISO’s job.
This starts at the board level, where teams struggle to find a common language for discussing risks and security investments with folks who don’t have any industry experience. Multiple CISOs talked about frameworks they had created, and had to recreate or change at each organization – we see this in the industry with teams trying to make comparisons to more familiar risks, like financial risk. Quantifying and explaining risk is “an area of extreme importance” but very low maturity in the industry.
One level down, security teams want to measure that their investments provide value and actually help improve security for their organization. As one CISO explained: “It’s hard to prove you’re getting what you think you’re getting.” Explaining their security priorities is difficult, with some teams mapping their priorities to the MITRE ATT&CK framework, an internal list of top threats, or collaborating with the business on risk prioritization. It’s exceedingly hard to define and move to something like probabilistic risk measurements. And, teams want to demonstrate that they’re safe enough, or justify further investment where needed: this is “where I spend most of my time.. how do we demonstrate we have a good security program?”
Asking for contributions from the business and justifying security controls that (might) add friction is another hurdle. So much of the work needed to make a security control effective isn’t done by the security team. To roll out any control, they need to really justify that it will have significant security impact, such as wipe out a whole class of issues. A CISO is worried about the perception from the CEO, who is “worried you’re adding friction to my barely profitable business.” CISOs are looking for strong evidence and data they can use to make decisions, and ways to communicate and measure minimum security requirements and security tech debt they ask their partner teams to take on.
Security tech stack
What the 80% use
My research revealed a security tech stack that was common across the majority of organizations (again, keep in mind the biased data set). I wasn’t explicitly seeking feedback on these vendors, but many folks volunteered their opinions:
- Cloud providers: 😐 AWS, then 😐 GCP, then 🙁 Azure are all widely in use. Those with Azure have some regrets: we thought “Microsoft would help get us into [government] markets… it has totally not happened.”
- Identity: 🙁 Okta and 😊 1Password. One participant said, “I hate Okta with all my soul… they’re the Microsoft of identity.” They didn’t even use Microsoft.
- MDM: 🙁 Jamf and 🙁 Intune.
- EDR: 😐 Crowdstrike, then 😐 SentinelOne, are both widely used. Crowdstrike was polarizing, with both strong positive and negative feedback.
- CSPM: 😊 Wiz, which people love. One CISO commented that they trusted Wiz, since they “bailed me out.”
- IaC: 😐 Terraform.
- Observability: 😐 Datadog.
- Data lake: 😐 Snowflake.
There are two spaces that stood out for not having any consistency: vulnerability scanners and SIEMs.
Vulnerability scanners
We have way too many vendor categories for vulnerabilities across code, containers, configs, and more: SAST, DAST, SCA, ASPM, CSPM, DSPM, … the list never ends (and changes every year). This is our own fault – we have no one to blame here but ourselves. One CISO lamented that they have “a whole portfolio” of scanners.
The main drivers of what tools to buy were value, cover-your-ass compliance, and cost – which helps explain why there are so many point solutions, and why users are so willing to replace them. I heard of at least a dozen different tools, including many open source tools. In rough order of most use: Snyk, Semgrep, Veracode, Tenable, SonarQube, CodeQL, Rapid7, AWS Inspector, Mend, Trivy, Clair, Socket, and Dependabot. There was serious consideration of open source tools: if I have to configure it anyways, should I do it myself? Is paying for this the best way to spend a significant chunk of my security budget?
Looking at the spread of scanners in most organizations, it’s not a surprise that vulnerability management – and especially a workflow for prioritizing and addressing vulnerabilities from multiple tools – as well as vendor sprawl are some of the top pain points I heard.
SIEMs
The trend in SIEMs is different: it’s organizations choosing to migrate off of Splunk over time, to a more modern SIEM like Panther, and then looking to migrate off of Panther to a lower cost solution if possible. “Nobody has come up with a Splunk replacement… there are a bunch of competitors, but no one seems to be able to knock them off the top of the stack.”
In rough order of use, SIEMs included: Splunk, Panther, Sumo Logic, ELK, RunReveal, Datadog, and Google Security Operations.
The main motivator to consider a migration is the cost of storage, and this move may be partly mitigated by choosing to stream a subset of logs only, filtering these with a tool like Cribl or LogSlash. The main requirement when looking for a new SIEM is query portability, to avoid getting locked into another SIEM. Frustration also comes from the work needed to ingest and normalize logs from various sources – there’s “no turnkey solution available,” with every solution requiring too much work to get set up. Again, not a surprise why SaaS logs and vendor sprawl are so painful.
Tools being built internally
I also asked folks what they were building or have built internally. Security teams have very limited engineering resources, so if they’re choosing to build something, it must truly be a priority, and something they can’t buy.
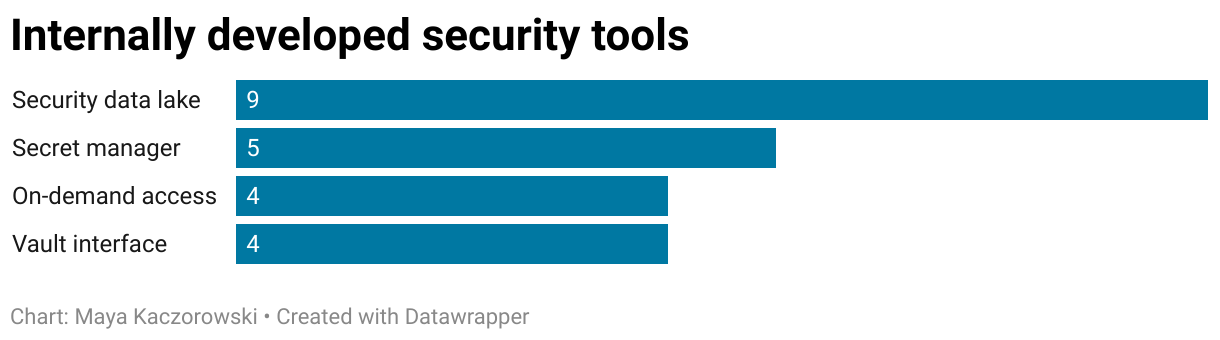
~20% of teams built a security data lake. This is an operational data store for security and compliance, including osquery logs from corp and prod devices, and cloud configuration scans from CloudQuery – this is more than just historical SIEM logs, but also asset information. The data lake can then be queried to find exceptions, look for TTPs, and verify controls.
~10% of teams built an on-demand access solution, to provide time-bound access to sensitive resources, like on-call access to prod, or support access to customer data. This may include an approval workflow, and is typically implemented by changing group membership in the identity provider. Although solutions like Opal exist, the heterogeneity of environments and the high cost of integration means that some organizations are choosing to build this themselves.
~10% of teams built a secret manager, and another ~10% built an interface to Vault. The secret managers were usually legacy – tools they might not choose to build themselves with what’s available today, but also tools that they aren’t incentivized to migrate off of. For those who built a Vault interface, this is usually a front-end interface to provide an improved developer experience with restricted functionality, since “using Vault isn’t intuitive… the tooling around it sucks.” It might also have a pluggable back-end to multiple regional instances of Vault, used for data locality or different environments.
What about AI?
Unprompted, AI barely came up as a security issue. (No, really, VCs! Also, please stop emailing me about this.) There is a lot of interest and excitement about using AI to improve security tooling, but far less about how to secure AI.
While not yet a pain point, security leaders are aware of AI security challenges. GenAI governance is the main concern, to ensure that only the teams who have been authorized to are using genAI, with only allowed data: just to check, “are you using the enterprise version?” This visibility and governance (rather than security per se) is being provided by tools like Lanai, Harmonic, and Kindo.
The next concern is preventing unauthorized data from being trained upon. This is just data governance: “You need to know what you’re protecting, and where it is.” This is a bit of a chicken and egg problem: they might not know exactly what and where their data is, and current DLP tools don’t do a great job of classifying non-traditional data, and “next gen DLP doesn’t really exist yet”; but they can’t train a model on their customers’ data to find it, as that’s explicitly what they’re trying to avoid.
For companies hosting their customers’ models, or serving multi-tenant models, workload isolation was a concern. They need an efficient way to isolate different customers’ code, models, or interactions, and gVisor is the current best option. A solution like Edera looks promising.
If there’s one takeaway I have – other than the fact that our work in security is never done, and our jobs are quite secure, in fact – it’s that a lot of the problems we’re facing aren’t new. Our industry cycles through technologies, and though new infrastructure like GenAI might need new tools to secure, it doesn’t need new concepts.
There are surprisingly few innovations that have really been step functions that wholesale eliminate classes of issues in the industry, such as hardware tokens or memory-safe languages. How can we get more of those, so that this list looks very different in 5 or 10 years?
The mention of any vendor in this blog post is not an endorsement. Disclaimer: I am an investor or advisor of Chainguard, CloudQuery, and RunReveal.